


Stable Audio 1.0, this new model sets a new standard by enabling the creation of high-quality, full tracks with coherent musical structures up to three minutes long at 44.1 kHz stereo.
Stable Audio 2.0 not only enhances the capabilities of text-to-audio generation but also introduces groundbreaking audio-to-audio functionalities, allowing users to transform uploaded audio samples using natural language prompts.
This latest iteration offers a host of new features designed to empower artists and musicians with unprecedented creative flexibility and control.
From generating complex musical compositions to customizing sound effects and performing style transfers, Stable Audio 2.0 opens up a world of possibilities for audio production.
Trained exclusively on a licensed dataset from the AudioSparx music library, Stable Audio 2.0 respects opt-out requests and ensures fair compensation for creators, maintaining ethical standards in AI development.
Available for free on the Stable Audio website and soon on the Stable Audio API, this model invites users to explore and innovate in the realm of AI-generated music.
Stable Audio 2.0 Features
Stable Audio 2.0 marks a significant leap forward in AI-generated audio, offering several key features and enhancements that distinguish it from its predecessor.
One of the standout capabilities is the production of high-quality, full-length tracks. Users can now generate songs with coherent musical structures up to three minutes long at 44.1 kHz stereo quality, ensuring a professional-grade audio experience.
Expanding beyond text-to-audio generation, Stable Audio 2.0 introduces audio-to-audio capabilities. This innovative feature allows users to upload audio samples and transform them using natural language prompts.
This update broadens the scope of sound effect generation and style transfer, giving artists and musicians greater flexibility and creative control over their projects.
The new model also supports the creation of melodies, backing tracks, stems, and a wide array of sound effects, enhancing the creative toolkit available to users.
Whether it’s the tapping on a keyboard, the roar of a crowd, or the hum of city streets, Stable Audio 2.0 enables the generation of diverse auditory elements that can elevate any audio project. One of the most exciting additions is the capability to transfer styles.
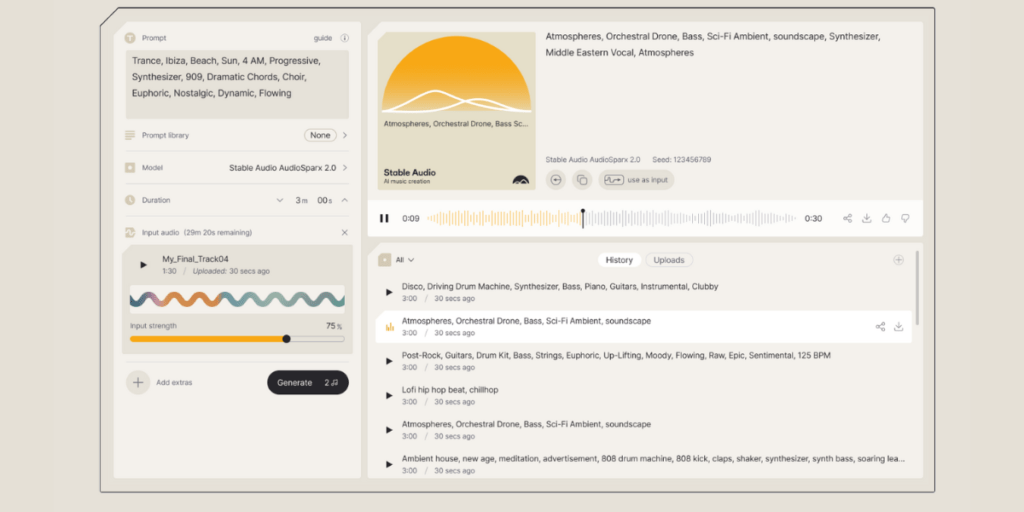
This feature allows users to seamlessly modify newly generated or uploaded audio to fit specific themes and tones, aligning with the unique requirements of their projects. The ability to customize the output ensures that artists can achieve the desired aesthetic and emotional impact in their work.
By building on the foundation of Stable Audio 1.0, which debuted in September 2023 as the first commercially viable AI music generation tool, Stable Audio 2.0 leverages advanced latent diffusion technology to deliver superior performance.
Named one of TIME’s Best Inventions of 2023, the original model has been significantly enhanced to offer even greater capabilities in this latest release.
Stable Audio 2.0 is available today for free on the Stable Audio website and will soon be accessible via the Stable Audio API, inviting users to explore and push the boundaries of AI-generated music.
New Functionalities
Stable Audio 2.0 introduces a range of new functionalities designed to enhance the creative process for artists and musicians.
Among these is the ability to generate full-length tracks. Unlike other models that may only produce short audio clips, Stable Audio 2.0 can create songs up to three minutes in length, complete with structured compositions including an intro, development, and outro, as well as stereo sound effects.
This ensures that users can produce tracks that are not only long enough for various applications but also maintain a coherent and professional quality throughout.
Another significant functionality is the new audio-to-audio generation capability. Users can now upload their own audio files and use natural language prompts to transform these samples into fully produced pieces.
This feature provides a high degree of creative freedom, allowing for extensive experimentation and customization.
Importantly, to protect intellectual property rights, all uploaded audio must be free of copyrighted material, and advanced content recognition technology is employed to enforce this rule.
The model also enhances the creation of variations and sound effects. Users can generate a wide range of sounds, from the subtle tapping of a keyboard to the immersive roar of a crowd or the ambient hum of city streets.
This diversity in sound generation opens up new possibilities for enhancing audio projects with rich and varied auditory elements.
Stable Audio 2.0 introduces a style transfer feature that allows users to modify audio outputs to fit specific styles and tones.
This functionality is particularly useful for aligning the audio with the thematic and emotional requirements of different projects, ensuring that the final output perfectly matches the intended aesthetic.
Technical Architecture
Stable Audio 2.0 leverages an advanced technical architecture to deliver high-quality audio generation. At the core of this system is a combination of an autoencoder and a diffusion transformer, each playing a crucial role in the model’s capabilities.
The autoencoder is designed to compress raw audio waveforms into much shorter representations while preserving essential features.
This process enables the model to focus on the most important aspects of the audio, filtering out less significant details and ensuring coherence in the generated tracks.
The autoencoder’s ability to condense and reconstruct audio effectively sets the foundation for generating high-quality outputs.
Complementing the autoencoder is the diffusion transformer, which replaces the previous U-Net architecture used in Stable Audio 1.0.
The DiT refines random noise into structured data incrementally, identifying intricate patterns and relationships within the audio.
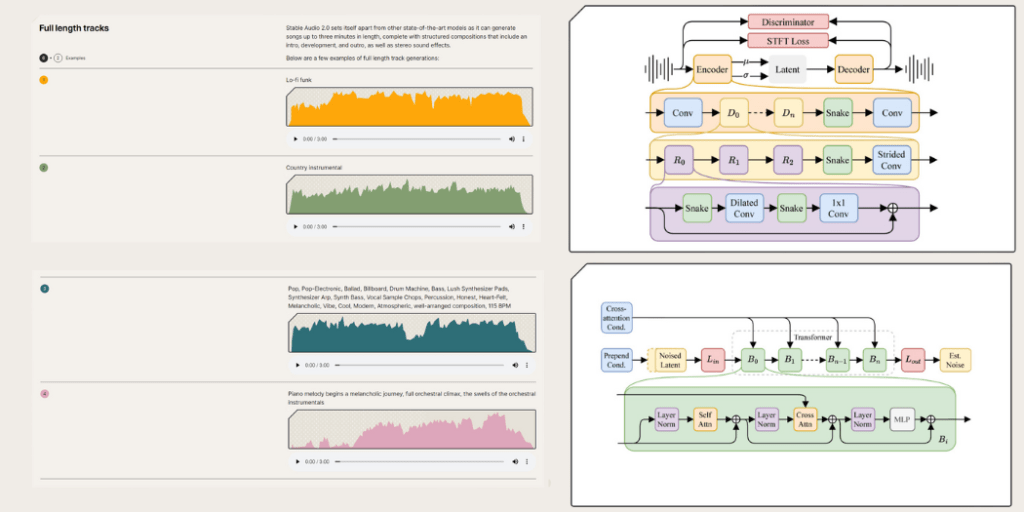
This method is particularly effective for handling long sequences, allowing the model to produce tracks with coherent musical structures that maintain their integrity over extended durations.
The enable Stable Audio 2.0 to recognize and reproduce large-scale musical structures, which are essential for creating full-length tracks.
The integration of these components results in a model that not only understands the nuances of musical compositions but also excels in generating audio that meets professional standards.
This sophisticated architecture is a significant improvement over previous models, ensuring that Stable Audio 2.0 can deliver on its promise of high-quality, coherent musical tracks.
The combination of advanced compression and refined noise reduction techniques makes it possible to generate complex audio pieces with a level of detail and accuracy that was previously unattainable in AI-generated music.
Ethical Considerations
Stable Audio 2.0 is designed with robust safeguards and ethical considerations to ensure responsible use and fair treatment of creators.
The model was trained exclusively on a licensed dataset from the AudioSparx music library, which includes over 800,000 audio files containing music, sound effects, and single-instrument stems, accompanied by corresponding text metadata.
Importantly, all artists whose work is part of this dataset were given the option to opt out of the training process, ensuring their preferences and rights are respected.
To further protect creators’ copyrights, Stable Audio 2.0 employs advanced content recognition technology through a partnership with Audible Magic. This technology powers real-time content matching to prevent copyright infringement by verifying that uploaded audio samples are free of copyrighted material.
This safeguard is crucial for maintaining compliance with intellectual property laws and protecting the rights of original creators.
Stable Audio 2.0’s terms of service explicitly require that users upload only non-copyrighted material, reinforcing the commitment to ethical usage.
This proactive approach not only safeguards the rights of content creators but also fosters a trustworthy environment for users exploring AI-generated audio.
By integrating these ethical considerations and safeguards, Stable Audio 2.0 ensures that the technology is used responsibly and that creators receive fair compensation and recognition for their work.
This commitment to ethical standards sets a positive example in the field of AI-generated content. It underscores the importance of respecting intellectual property rights in the digital age.
Stable Audio 2.0 represents a significant advancement in AI-generated audio, offering features like high-quality, full-length tracks, audio-to-audio generation, and style transfer.
Built on a sophisticated technical architecture, it provides artists and musicians with unparalleled creative tools.
With robust safeguards to protect creators’ rights and a commitment to ethical standards, Stable Audio 2.0 is available for free on the Stable Audio website, inviting users to explore its innovative capabilities.