
OpenAI’s release of ChatGPT marked a monumental shift in the artificial intelligence landscape, capturing global attention with its advanced generative capabilities.
This milestone represented a significant advancement in AI, predominantly driven by Large Language Models focused on text processing.
Multimodal AI transcends the traditional boundaries set by unimodal systems, which rely solely on one type of data input and output, typically text.
Multimodal AI Power of Integrated Data embraces the complexity of human cognition by integrating multiple forms of data, including text, images, audio, and video, to create more comprehensive and context-aware AI systems.
This shift enhances the interaction between humans and machines. It paves the way towards achieving Artificial General Intelligence, a type of AI that can understand, learn, and perform a wide array of tasks similar to a human.
Multimodal AI
Multimodal AI emerges as a sophisticated advancement that strives to mimic the integrative processing capabilities of the human brain.
Unlike traditional AI models that are restricted to single types of data or modalities—primarily text—multimodal AI can handle and synthesize a variety of data types, including text, images, audio, and video.
This capability represents a significant step towards developing Artificial General Intelligence, which aspires to perform any intellectual task a human can.
Humans do not rely on just one sense to understand the world; instead, they integrate inputs from sight, sound, touch, taste, and smell to form a comprehensive view of their environment.
This multimodal perception is crucial for complex decision-making and learning. Similarly, multimodal AI aims to replicate this sensory integration, allowing machines to gain a richer understanding and responsiveness to the complexities of real-world environments.
The initial generative AI models, such as ChatGPT, were primarily unimodal, designed to process and generate text based on text inputs alone.
This focus was driven by the accessibility and abundance of textual data and the relative simplicity of processing text compared to more complex data types like video or audio.
These models are limited in scope, as they do not utilize the full spectrum of human-like sensory data that could enhance decision-making or creative outputs.

Multimodal AI systems, by contrast, are trained on diverse datasets comprising various data types. For instance, they might learn to correlate textual descriptions with corresponding images, understand speech through audio inputs, or interpret emotions from video data.
This training enables the AI to perform tasks requiring a more nuanced understanding of the world, such as recognizing objects in a video while understanding spoken descriptions.
The core challenge in multimodal AI is integrating these diverse data types into a coherent model that can process and generate information across modalities.
This involves sophisticated data fusion techniques, combining information from different sensory inputs. Data fusion can occur at various stages of processing.
Concepts of Multimodal AI
Multimodal AI is a burgeoning field that integrates insights from various domains of artificial intelligence to process and generate multiple data types simultaneously.
This capability substantially evolves from traditional AI models, allowing for a more holistic data analysis and interpretation approach.
Multimodal generative AI models are primarily built using a neural network architecture called the Transformer. Developed by Google researchers, Transformers utilize an encoder-decoder structure and are renowned for their efficiency in handling large datasets.
The key to the Transformer’s effectiveness is the attention mechanism. It allows the model to weigh the importance of different words in a sentence or elements in data regardless of their sequential position.
This feature is crucial for integrating multiple data types, as it helps the model to focus on the most relevant parts of the input for generating responses.
This technique involves merging different modalities at the beginning of the processing pipeline. The integrated data is then fed into the AI model, allowing it to learn from a unified dataset that combines all relevant features into a single representation.
Each modality is processed up to a certain point separately, allowing for preliminary independent feature extraction. These features are then combined and processed in subsequent layers of the model, which can be particularly useful for capturing more complex interdependencies between modalities.
This approach takes the outputs of separately trained models for each modality and combines them at a later stage, often at the decision level. Late fusion is advantageous in scenarios where each data type is best processed with its specialized model before its results are synthesized.
Multimodal AI is designed to simultaneously handle inputs such as text, images, audio, and video. This allows it to perform tasks that require a broader understanding than any single data type could provide.
By training on multimodal data, these systems learn to recognize patterns that span different data types, such as associating spoken words with images or linking text descriptions with video content.
One of the main challenges in multimodal AI is effectively integrating and synchronizing data from different modalities. Each data type has inherent properties and processing requirements, making creating a model that can seamlessly handle them challenging.
Ensuring that no single modality dominates the learning process requires careful neural network and training process design. This balance is crucial for the model to perform well on tasks that require an equal understanding of all input types.
Technologies Powering Multimodal AI
Each technology contributes unique capabilities that enable AI systems to process and understand multiple data types simultaneously. Below, we explore the key technologies integral to powering multimodal AI, highlighting how they work together to enhance AI’s potential.
Deep learning forms the backbone of most modern AI systems, including multimodal AI. It involves using artificial neural networks with multiple layers that can learn complex patterns in large amounts of data.
In multimodal systems, deep learning algorithms are trained to detect patterns and features from diverse data types—text, images, audio, and video—enabling these systems to perform tasks that require a nuanced understanding of different inputs.
NLP is a critical domain within AI that focuses on enabling computers to understand, interpret, and generate human language.
This includes tasks like translation, sentiment analysis, and chatbot functionality. In multimodal AI, NLP processes textual data and integrates it with other data types. For instance, NLP can help an AI system understand a spoken command and relate it to visual data, enhancing interaction capabilities.
Computer vision allows machines to ‘see’ by interpreting and making sense of visual data from the environment, such as images and videos. This includes object recognition, facial recognition, and scene reconstruction.
In a multimodal context, computer vision technologies are used to process and analyze visual inputs, which can be combined with text or audio data to provide a more comprehensive understanding of a scene or event.
Audio processing involves techniques that enable AI systems to analyze and generate audio data. This includes speech recognition, music generation, and sound effects identification.
Audio processing technologies are essential for multimodal AI models that interpret or generate spoken content, enabling them to support applications such as virtual assistants, automated transcription services, and more interactive entertainment systems.
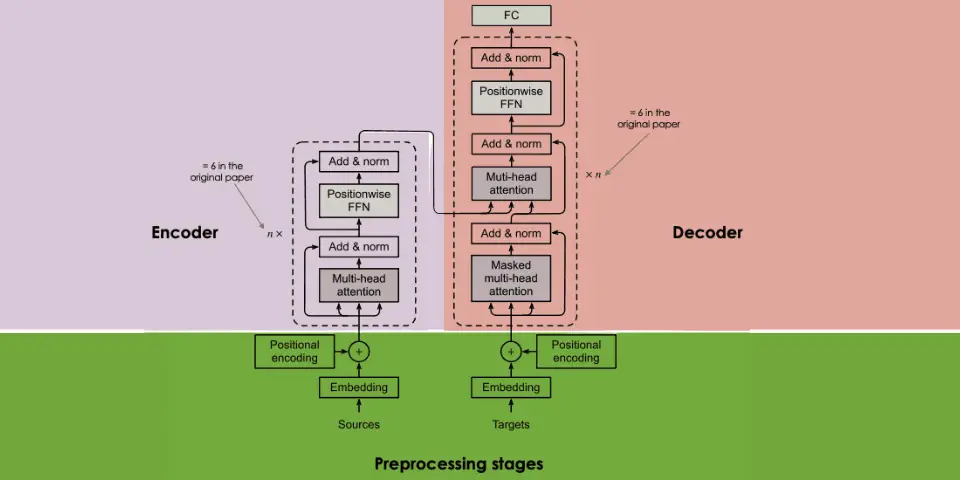
Transformers are a type of neural network architecture that has revolutionized the field of AI due to its ability to handle sequences of data more effectively than previous models.
The Transformer’s architecture, particularly its use of self-attention mechanisms, allows it to process different data types in parallel and integrate information across modalities efficiently.
Data fusion is crucial for meaningfully combining information from various sensors or data streams. Techniques vary from simple concatenation of features to more complex integrative approaches that maintain the context and relationships between data from different sources.
Effective data fusion enables multimodal AI systems to utilize combined data from text, images, sound, and other sources to make decisions or generate outputs that are richer and more context-aware than those derived from any single data type alone.
Applications of Multimodal AI
Multimodal AI leverages the integration of multiple types of data—text, images, audio, and video—to enhance the capabilities of AI systems, enabling them to perform more complex and varied tasks.
This approach broadens the scope of AI applications and increases their effectiveness and accuracy. Below, we explore some key areas where multimodal AI is making significant impacts.
Multimodal AI extends the functionality of traditional text-based generative models by incorporating other modalities, such as visual and audio inputs. This can improve user interactions with AI systems, making them more intuitive and responsive.
Models like GPT-4 Turbo and DALL-E not only accept text inputs but can also generate or modify images based on textual descriptions, offering new ways for users to engage with creative content.
Self-driving cars use multimodal AI to process inputs from multiple sensors—cameras, radar, and lidar—to navigate and make real-time decisions. This integration is critical for accurately interpreting the car’s surroundings and reacting to dynamic road conditions.
By combining these modalities, autonomous vehicles can achieve higher situational awareness and operational safety, potentially reducing accidents and improving traffic flow.
In the medical field, multimodal AI can analyze data from various sources—clinical notes, imaging, lab results, and genetic information—to provide more comprehensive diagnostic insights.
This technology supports the development of customized treatment plans by integrating and analyzing diverse health data, leading to better patient outcomes.
Multimodal AI is pivotal in combining satellite data, ground sensors, and drones to monitor environmental changes and predict climate phenomena.
This can be used to track greenhouse gas emissions, predict extreme weather events, and improve agricultural practices through precision farming techniques.
In the entertainment industry, multimodal AI creates more engaging and interactive media. It can generate music, edit videos, or create virtual realities based on textual inputs or user interactions.
Game development can also benefit from multimodal AI, which can create more lifelike and responsive environments or characters that react to voice commands and physical gestures.
AI-driven chatbots can now handle not just text but also voice and video inputs, providing a richer interaction experience for customers.
These chatbots can interact with other smart devices, providing users with more efficient and effective customer service, from troubleshooting to personalized recommendations.
Multimodal AI can create dynamic educational tools that respond to verbal questions and written inputs, adapting the learning content to the student’s needs.
In medical or military training, multimodal AI can simulate real-world scenarios, combining visual, textual, and auditory information to provide a comprehensive learning experience.
Risks of Multimodal AI
While multimodal AI offers remarkable advancements in processing and synthesizing various data types, it also introduces specific risks that need careful consideration.
These risks can impact users, organizations, and broader society, stemming from the inherent characteristics of the technology as well as its application contexts.
Multimodal AI systems, especially those using deep learning and complex data fusion methods, are often considered “black boxes” due to their opaque decision-making processes. This lack of transparency can make it difficult to understand or predict the system’s behavior, complicating efforts to identify errors or biases.
The complexity of these systems also makes troubleshooting and auditing a challenge. This can lead to difficulties in ensuring the reliability and safety of AI applications, particularly in critical areas like healthcare or autonomous driving.
Multimodal AI often requires extensive data from various sources, including sensitive personal information. There is a risk of exposure or misuse of this data, especially if security measures are inadequate.
Compliance with Regulations: Ensuring that data handling and processing comply with international data protection regulations is crucial but challenging, given the diverse sources and types of data involved.
If the data used to train multimodal AI systems is biased, the systems will likely perpetuate these biases.

This can lead to unfair or discriminatory outcomes, particularly in social interactions, employment, and law enforcement applications.
Addressing biases in multimodal AI is more complex due to integrating multiple data types, each with its potential biases and their interactions.
Developing and maintaining multimodal AI systems requires significant resources, which can lead to a concentration of power in the hands of a few large tech companies. This could stifle innovation and limit access to these powerful tools.
The high cost and complexity of multimodal AI technologies may prevent smaller companies and startups from entering the market, potentially reducing competition and innovation.
There’s a risk that increasing reliance on multimodal AI for decision-making could lead to de-skilling the human workforce, making people overly dependent on AI systems.
Automation through AI could also lead to job displacement in specific sectors, raising social and economic concerns about the future of employment.
The training and operation of large-scale multimodal AI models require significant computational power, which consumes much energy. This contributes to the carbon footprint of AI technologies.
The Future of Multimodal AI
Future developments in multimodal AI are expected to achieve more sophisticated integration of sensory data, mimicking human cognitive abilities more closely. This could lead to AI systems that understand and interact with their environment in a genuinely human-like manner.
As the technology matures, we will likely see its application expanding into new fields such as personalized education, advanced healthcare diagnostics, and integrated smart city infrastructures, which will benefit from the nuanced understanding that multimodal AI provides.
Efforts to standardize how data is shared and processed across different AI systems will improve interoperability, making it easier to build and scale multimodal AI solutions across platforms and industries.

The future will likely witness the rise of collaborative ecosystems where AI systems from different domains communicate and work together, enhancing technological solutions’ overall efficiency and effectiveness.
There will be an increased emphasis on developing comprehensive regulatory frameworks that address the unique challenges posed by multimodal AI, including privacy, bias, and transparency.
Organizations will increasingly adopt principles of ethical AI by design, incorporating considerations like fairness and accountability right from the initial stages of AI system development.
New training techniques that reduce AI models’ computational and environmental costs are likely a key area of research. This includes methods to train AI with less data and energy without compromising performance.
These approaches will become more prevalent, enabling multimodal AI systems to learn from fewer examples and adapt to new tasks with minimal additional input.
As AI systems become more capable and ubiquitous, ensuring their security against hacking and misuse will become more critical. This includes developing more robust methods to protect AI from adversarial attacks and ensuring that AI systems can’t be used maliciously.
A greater focus will be on building resilient AI systems that can operate reliably in various conditions and recover quickly from disruptions.
Efforts to democratize access to AI technologies will intensify, with more open-source platforms and tools becoming available. This will help reduce the monopoly of big tech companies and foster a more inclusive AI development landscape.
Final Thoughts
As we have seen, multimodal AI can understand and process complex inputs from diverse sources—text, images, audio, and video—bringing us closer than ever to developing AI systems that can mimic human sensory and cognitive capabilities.
From enhancing generative AI with augmented capabilities to driving innovations in autonomous vehicles and biomedicine, multimodal AI sets the stage for significant advancements across various sectors. It promises to improve operational efficiencies and create more personalized and accessible services like education, healthcare, and entertainment.
Journey towards fully realizing the benefits of multimodal AI has its challenges. Technical hurdles, ethical concerns, privacy issues, and the environmental impact of deploying AI at scale are critical issues that must be addressed.
The complexity of integrating and synchronizing multiple data types demands advanced technological solutions and a thoughtful approach to the design and deployment of these systems, emphasizing transparency, fairness, and sustainability.
It will be imperative to continue developing robust frameworks and policies that guide the ethical use of AI, ensuring that multimodal systems enhance societal well-being without exacerbating inequalities or compromising privacy and security.

